1067
Как отличить текст ИИ от человеческого: российские учёные раскрыли алгоритм
Новая методика из Сколтеха и МФТИ делает детекторы нейросетевых текстов прозрачными

Команда учёных из Сколковского института науки и технологий (Сколтех), Московского физико-технического института (МФТИ), Института искусственного интеллекта AIRI и других партнёрских организаций предложила новый подход к распознаванию текстов, созданных искусственным интеллектом. В основе их метода лежит анализ внутренних слоёв нейросетей с использованием разреженных автокодировщиков (Sparse Autoencoders, SAE), позволяющих извлечь интерпретируемые признаки стиля, сложности и структурных особенностей текста.
Работа принята на международную конференцию Findings of ACL 2025 и уже опубликована в виде препринта на arXiv. Это один из первых российских проектов, который не просто предлагает улучшить точность детекции ИИ-текстов, но и делает её понятной для человека. Ведь главная проблема текущих решений — их «чёрный ящик»: они дают бинарный ответ «ИИ» или «человек», но не объясняют, почему принято такое решение.
Исследователи решили отказаться от такой модели и сконцентрировались на интерпретации внутренних состояний языковых моделей. Используя SAE, они «разложили» нейросетевую активность на тысячи числовых признаков — каждый из которых можно интерпретировать как отражение определённой черты текста. Например, один признак может отражать синтаксическую сложность, другой — уверенность в формулировках, третий — склонность к повторениям или избытку вводных конструкций.
По словам Лаиды Кушнаревой, старшего академического консультанта Huawei, тексты, сгенерированные ИИ, зачастую можно распознать по слишком формальному стилю, затянутым вступлениям и дублирующимся формулировкам. Однако большинство детекторов не позволяют увидеть, в какой степени эти признаки выражены. Новая методика, напротив, позволяет декомпозировать текст на понятные человеку показатели, с высокой точностью указывающие на его происхождение.
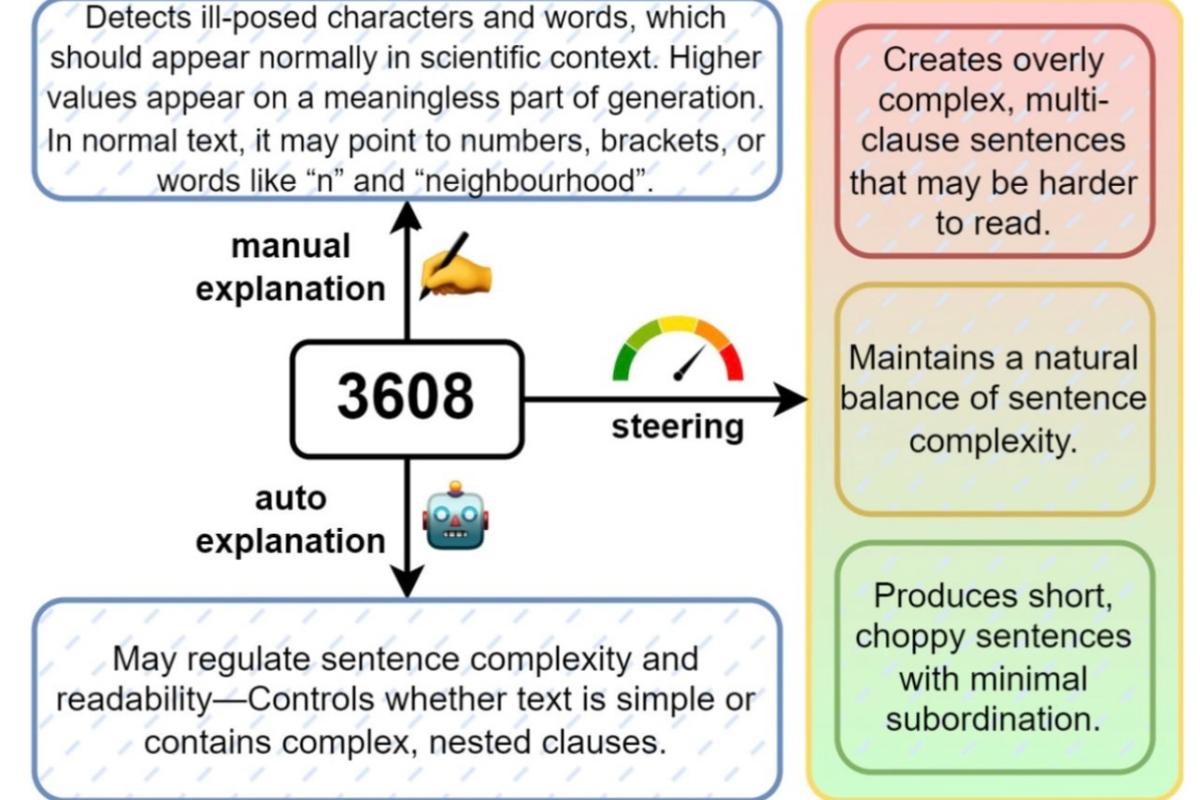
Особенность подхода — в возможности не только фиксировать наличие признаков, но и управлять ими. Например, усиливая признак академичности, можно добиться от модели более сложного и формального языка, а ослабляя — получить простые, разговорные конструкции. Один из «универсальных» признаков, №3608, оказался связан с синтаксической перегруженностью: если его усиливать, модель пишет запутанно, если ослаблять — рублено и коротко.
В ходе работы учёные обучили классификатор, способный распознавать сгенерированные тексты по этим признакам. Более того, они показали, что с помощью SAE можно выявлять и попытки намеренного обмана: добавление лишних пробелов, символов или артиклей для «маскировки» ИИ-текста также распознаётся с высокой точностью.
Отдельный интерес представляет возможность адаптации метода под конкретные жанры. Так, для научных статей характерны одни признаки, для отзывов — другие, а для образовательных текстов — третьи. Это делает систему гибкой и применимой как в академической среде, так и в журналистике, образовании и борьбе с фейками.
Студентка МФТИ Анастасия Вознюк отмечает, что методика позволяет не только определять источник текста, но и «рулить» генерацией. Это даёт мощный инструмент для создания более качественного ИИ-контента и одновременно для его верификации.
Авторы подчёркивают: если задать языковой модели персонализированный стиль — например, подражание конкретному человеку — то узнаваемые ИИ-признаки могут исчезнуть. Это делает задачу детекции сложнее, но в то же время подчёркивает важность интерпретируемых методов, способных разбирать текст «по косточкам».
Разработанная система сочетает автоматический анализ, ручную интерпретацию и технику «управления» генерацией. В перспективе она может стать основой для более прозрачных детекторов, которые не просто выносят вердикт, но и обосновывают его. Это особенно важно для преподавателей, редакторов, исследователей дезинформации и всех, кто сталкивается с необходимостью различать ИИ и человека.
ИЗНАНКА
Работа исследователей знаменует поворот от «чёрных ящиков» в сторону интерпретируемых и объяснимых моделей в сфере искусственного интеллекта. Это важно не только для научного сообщества, но и для преподавателей, журналистов, аналитиков, чья деятельность всё чаще сталкивается с задачей верификации текстов. Использование автокодировщиков позволяет вскрывать закономерности и шаблоны, по которым ИИ строит текст, а значит — даёт ключ к управлению генерацией, её распознаванию и, в перспективе, даже обучению более гибких и прозрачных моделей. Россия демонстрирует, что может быть на передовой не только в области прикладного ИИ, но и в формировании этических стандартов его использования.
Фото: Alena Plotnikova, unsplash.com.
Читайте, ставьте лайки, следите за обновлениями в наших социальных сетях и присылайте свои материалы в редакцию.
ИЗНАНКА — другая сторона событий.



МВД призвало россиян меньше улыбаться для предотвращения несанкционированных платежей
Улыбка может стать причиной финансовых потерь: за год зафиксировано 43 случая ...
/ / Интересное
Автор: Денис Иванов

Прибыли российский рыбаков значительно снизились
А долги достигли триллиона рублей
/ / Интересное
Автор: Дмитрий Зорин
ВОЗ одобрила первую вакцину против оспы обезьян: новый этап в борьбе с вирусом mpox
Препарат MVA-BN, разработанный компанией Bavarian Nordic, получил официальное ...
/ / Интересное
Автор: Дарья Никитская